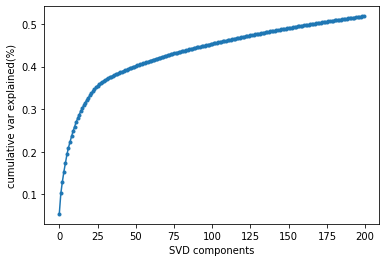
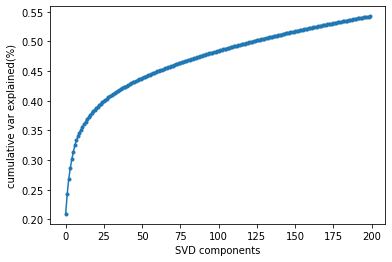
A recommender system is a type of information filtering system that predicts a user’s preferences for items (such as movies, books, music, products, etc.) and suggests relevant items to the user. These systems are widely used in e-commerce platforms, streaming services, social media platforms, and many other applications where personalized recommendations can enhance user experience and engagement.
There are several types of recommender systems, including:
Collaborative Filtering: This approach recommends items based on the preferences of users who have similar tastes. It doesn’t require explicit knowledge about the items or users, but rather relies on the patterns and similarities in user behavior.
Content-Based Filtering: Content-based filtering recommends items based on their attributes and features. It analyzes the characteristics of both the items and the user’s preferences to make recommendations. For example, recommending movies based on their genre, actors, directors, etc., and matching them with the user’s historical preferences.
Hybrid Recommender Systems: Hybrid systems combine multiple recommendation techniques to provide more accurate and diverse recommendations. For instance, combining collaborative filtering and content-based filtering to leverage the strengths of both approaches.
Knowledge-Based Recommender Systems: Knowledge-based systems recommend items based on explicit knowledge about user preferences, domain-specific rules, or constraints. These systems are often used in domains where there is rich domain knowledge available.
Context-Aware Recommender Systems: Context-aware systems take into account contextual information such as time, location, and device used when making recommendations. For example, recommending nearby restaurants based on a user’s current location and time of day.
Collaborative Filtering
import numpy as np
import pandas as pd
import sys
movies = pd.read_csv("./ml-20m/movies.csv")
tags = pd.read_csv("./ml-20m/tags.csv")
ratings = pd.read_csv("./ml-20m/ratings.csv", nrows=16000000)
# Restrict to users that have rated atleast 60 movies
ratings_df = ratings.groupby('userId').filter(lambda x: len(x) >=60)
ratings_df.shape
(14248972, 3)
ratings.shape
(16000000, 3)
len(ratings.userId.unique())
110725
len(ratings_df.userId.unique())
60448
# whihc all movies are there in ratings_df, keep only those in movies
ratings_movie_list = ratings_df['movieId'].unique().tolist()
movies = movies[movies['movieId'].isin(ratings_movie_list)]
movies.head()
from sklearn.metrics.pairwise import cosine_similarity
latent_matrix_df1.head()
0
1
2
3
4
5
6
7
8
9
...
190
191
192
193
194
195
196
197
198
199
Toy Story (1995)
0.027829
0.053107
0.019021
0.003907
0.005143
-0.027165
0.117464
-0.000203
0.000751
0.073886
...
-0.072060
0.014005
-0.030398
0.085778
0.211589
-0.046935
0.008914
0.015430
0.035303
-0.034852
Jumanji (1995)
0.011114
0.011237
0.025765
0.002484
0.014320
-0.001906
0.070994
-0.001397
0.008939
0.040755
...
0.017030
0.026041
0.014499
0.021231
-0.076609
-0.022787
0.054812
-0.017474
0.044199
-0.005890
Grumpier Old Men (1995)
0.040006
0.073972
-0.004636
-0.001118
0.031234
0.002447
-0.003453
0.000312
-0.001469
0.000665
...
0.021166
-0.003256
-0.014490
0.009730
-0.000665
-0.009319
0.000651
0.005782
-0.006482
0.036551
Waiting to Exhale (1995)
0.138340
0.076832
-0.021021
-0.002120
0.100808
0.013420
-0.012406
-0.003615
-0.006283
-0.002056
...
0.037234
0.028600
0.028611
-0.039458
-0.026834
-0.080583
0.047081
-0.010145
-0.005737
0.013725
Father of the Bride Part II (1995)
0.040096
0.084344
0.000854
0.000621
-0.013870
-0.000925
0.013931
0.006003
0.006188
0.011663
...
-0.029974
-0.014503
0.007450
0.044511
-0.000263
0.021819
0.004452
-0.039057
0.003836
0.003095
5 rows × 200 columns
latent_matrix_df2.head()
0
1
2
3
4
5
6
7
8
9
...
190
191
192
193
194
195
196
197
198
199
Toy Story (1995)
503.065269
-10.274285
118.147003
63.001323
33.324811
144.449895
-58.370170
58.839586
-50.801258
7.799550
...
-17.939855
-6.105493
13.302291
10.795169
-6.692900
-19.925751
8.026037
-17.779819
-3.730701
-11.210057
Jumanji (1995)
226.951509
-6.880712
142.044769
-38.659399
-34.455545
9.189622
-59.369870
43.351875
19.546100
-23.091564
...
-5.759097
15.838553
-4.651140
-7.410019
3.693425
12.570774
-3.953578
24.891350
10.353275
3.837859
Grumpier Old Men (1995)
94.293293
-45.533961
61.644364
-38.511678
-28.622765
-0.040053
-3.608147
1.412690
-17.248191
-29.525224
...
-0.670059
1.097869
-2.833690
-2.598111
-3.171674
-3.332366
4.101573
-3.049846
4.151136
-5.025944
Waiting to Exhale (1995)
23.234759
-25.256543
18.811186
-7.308903
-25.304709
0.539134
-0.387492
3.263833
-4.996824
2.722049
...
0.020090
-1.532013
-2.560055
-0.007939
-1.131231
0.192202
0.356880
-3.906472
-0.169543
-1.063388
Father of the Bride Part II (1995)
80.873515
-40.008944
67.371184
-34.720191
-44.404007
13.227772
-10.653996
8.077569
-11.464432
-18.275107
...
-0.786211
-0.501860
-4.795863
-3.421932
-3.465008
3.484481
0.667434
-0.128325
3.316472
-3.240816
5 rows × 200 columns
# Check similaruty of movie with content and collaboratice matricess
movie_content_vector = np.array(latent_matrix_df1.loc['Toy Story (1995)']).reshape(1,-1)
movie_collab_vector = np.array(latent_matrix_df2.loc['Toy Story (1995)']).reshape(1,-1)